안녕하세요 반갑습니다.
오랜만에 포스팅하려니 어떻게 글을 시작해야 할 지 막막하네요. 역시 뭐든 꾸준히 하는게 중요한거 같습니다.
아무튼 오늘 포스팅할 글은 Kafka 입니다. 카프카 중에서도 python코드를 통해 원격으로 Consumer를 구현해 볼건데요 이게 구글에 검색하면 나옵니다. 나오는데 이게 저처럼 GCP 같은 퍼블릭 클라우드를 쓰시는 분들은 잘 안될 수가 있어요. 그래서 이번에 제가 한 방식을 공유해보려고합니다.
우선 Kafka가 뭐냐??
아파치 카프카(Apache Kafka)는 아파치 소프트웨어 재단이 스칼라로 개발한 오픈 소스 메시지 브로커 프로젝트이다. 이 프로젝트는 실시간 데이터 피드를 관리하기 위해 통일된, 높은 처리량, 낮은 지연시간을 지닌 플랫폼을 제공하는 것이 목표이다. 요컨대 분산 트랜잭션 로그로 구성된[4], 상당히 확장 가능한 pub/sub 메시지 큐로 정의할 수 있으며, 스트리밍 데이터를 처리하기 위한 기업 인프라를 위한 고부가 가치 기능이다.
라고 위키백과에 적혀있는데 좀 쉽게 설명하자면 데이터를 저장하는데 있어서 안정성과 속도를 보장해 주는 도구라고 생각하시면됩니다.
예를 들어 서버 한 곳에서만 데이터를 수집하면 그 서버가 망가지거나 예기치못한 사고로 수집이 끊길 수 있잖아요? 그걸 이제 클러스터로 구축해서 여러 곳에서 수집을 해서 데이터가 안끊기게 하는 안정성을 보장해주고,
그 안끊기는 데이터를 잘 수집해서 쓸 곳에 똑똑하게 소비할 수 있게 하는 도구입니다.
아무튼 이런 카프카는 데이터 플랫폼 쪽에서 많이 사용되는데 자세히 알아보려면 브로커, 프로듀서, 컨슈머, 커넥터 등등의 개 그지같은 용어들을 공부하셔야 합니다.
항상 느끼는거지만 무언가를 공부할 때 이러한 용어를 익히는 과정이 참 고통스럽습니다.
하지만 본 포스팅은 카프카 개념 및 구축이 아니기 때문에 공식 도큐먼트 주소를 올리는 것으로 넘어갑니다. ^^
https://kafka.apache.org/documentation/
자 이제 본격적으로 우리가 원하는 python 원격 컨슈머에 대해 포스팅을 해볼텐데요 우선 제가 구축한 환경은 다음 그림과 같습니다.
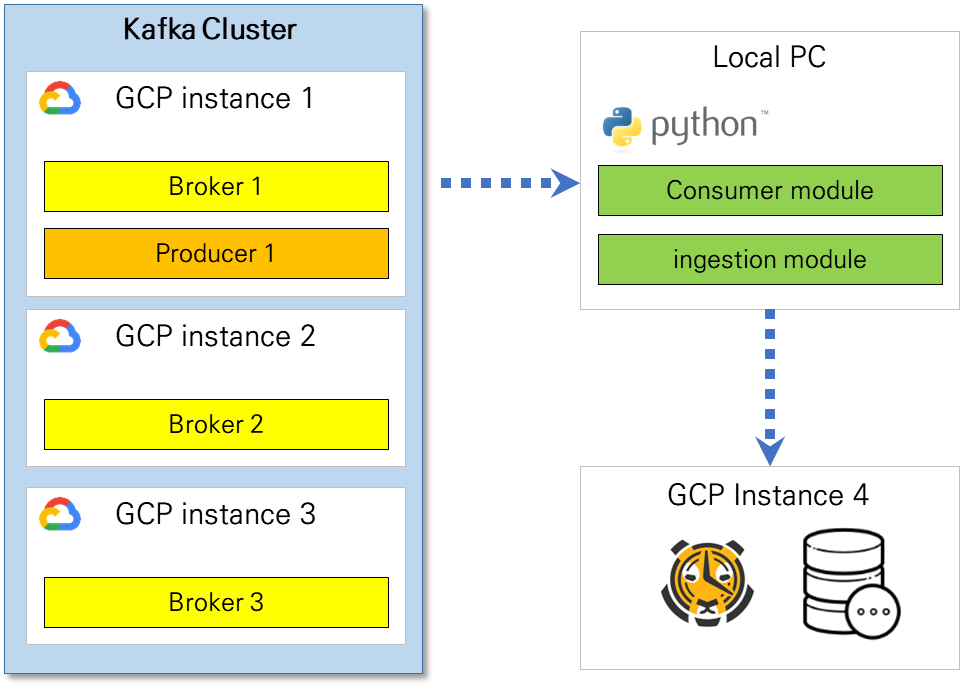
데이터 저장모듈까지는 이 포스팅에서 주제가 벗어나기때문에 컨슈머 부분에 대한 코드만 확인해보도록합니다.
if __name__ == "__main__":
topic_name = "test"
consumer = KafkaConsumer(
topic_name,
bootstrap_servers=[
"34.xx.xx.xx:9092",
"34.xx.xx.xx:9092",
"34.xx.xx.xx:9092",
],
auto_offset_reset="latest",
enable_auto_commit=True,
group_id="test",
value_deserializer=lambda x: loads(x.decode("utf-8")),
consumer_timeout_ms=1000,
)
print(consumer.topics())
print("[begin] get consumer list")
for message in consumer:
print(
"Topic: %s, Partition: %d, Offset: %d, Key: %s, Value: %s"
% (
message.topic,
message.partition,
message.offset,
message.key,
message.value,
)
)
print("[end] get consumer list")이거 처럼 흔히 구글검색해서 나오는 부분처럼 코드를 짜줍니다. bootstrap_servers 부분에 GCP 인스턴스의 외부IP 도 입력해주구요.
근데 해당 코드를 실행하면 컨슈머에서 연결은 되는거 같은데 데이터를 받아오지 못합니다. 전체 구조그림에서 카프카 클러스터에서 해당코드를 실행하면 똑바로 소비하지만 클러스터를 벗어난 외부에서는 연결은 되지만 소비를 못하는 아주 개같은 상황이 발생하는데요.
해당이유는 GCP의 특성때문입니다. https://www.confluent.io/blog/kafka-listeners-explained/ 해당 글의 옵션2 부분 외부주소에서 로컬을 확인 할 수 없을 때 (External address is NOT resolvable locally) 이런문제가 발생하는데
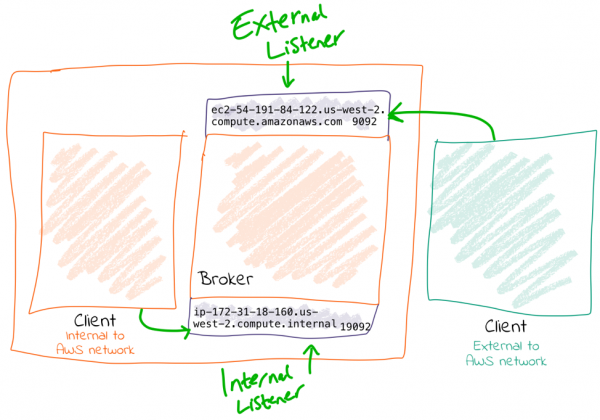
AWS나 GCP로 인스턴스를 구축하신 분들은 ifconfig를 통해 한 번 확인해 보시면 내부 주소만 검색되고 외부 IP는 검색이 안되는 경우가 있을 겁니다. 이런경우에는 카프카 config 파일을 수정해줘야합니다.
kafka config 파일에서 internal과 External을 나눠서 입력해줘야합니다.
listeners=INTERNAL://0.0.0.0:19092,EXTERNAL://0.0.0.0:9092
listener.security.protocol.map=INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
advertised.listeners=INTERNAL://<내부IP 10.xx.xx.xx>:19092,EXTERNAL://<외부IP 34.xx.xx.xx>:9092
inter.broker.listener.name=INTERNAL
이렇게 설정을 바꿔주고 카프카를 다시 실행하고 프로듀서 실행 후 컨슈머를 진행해보면 놀랍게도 깔끔하게 데이터를 받아옵니다.
'기타' 카테고리의 다른 글
| [Kafka] 데이터 잘못 넣었을 때 오프셋 초기화하기 (offset reset) (0) | 2024.01.19 |
|---|---|
| [redis] Postgresql(timescaledb)에 저장된 데이터를 시간단위로 redis에 옮기기 (0) | 2023.03.18 |
| Jenkins 서버 해킹 비트코인(모네로) 채굴 (2) | 2021.12.28 |
| 연구실 안전교육 스킵(배속)하는법 2 (15) | 2021.12.10 |
| GCP 인스턴스 ssh 접속 키 만들기 (0) | 2021.11.25 |


